

"As the largest open ecosystem in history, the Web is a tremendous utility, with more than 1.5B active websites on the Internet today, serving nearly 4.5B web users across the world. This kind of diversity (geography, device, content, and more) can only be facilitated by the open web platform."
This would be the uber pitch for Chrome Dev Summit this year: elevating the web platform.
Last month I was in San Francisco for CDS 2019, my first time attending the conference in person. For those of you who couldn’t attend CDS this year or haven’t yet gotten around watching all the sessions on their Youtube channel, here are my notes and thoughts about almost everything that was announced that you need to know!
Almost everything you say? Well then, buckle up, for this is going to be a long article!
Bridging the “app gap”
The web is surely a powerful platform. But there’s still so much that native apps can do that web apps today can not. Think about even some simple things that naturally come to your mind when picturing installed native applications on your phones or computers: accessing contacts or working directly on files on your device, background syncs at regular intervals, system-level cross-app sharing capabilities and such. This is what we call the “native app gap”. And we’re betting that’s there a real need for closing it.
In their natural progression, browsers have become viable, full-fledged application runtimes.
Over the last decade, “the browser” has become so much more than a simple tool for accessing information on the web. It is perhaps the most widely-known publicly-used piece of software that there is, yet so heavily underrated at its sophistication. In their natural progression, browsers have become viable, full-fledged application runtimes - containers for not only delivering but also capable of deploying and running a very large variety of cross-platform applications. Technologies arising out of browser engines have been used for a while to build massively successful desktop applications; browsers themselves have been used as the basis of building entire operating system UI and even run complex real-time 3D games at a performance that is getting closer and closer to native speeds every day. With that train of thought, it seems almost inevitable that the browserverse would sooner or later tackle the problem of being able to impart the average-joe web app the power to do things native apps can.

If I had to bet, the Web combined with its reach and ubiquitous platform support is probably going to become one of the best and perhaps most popular mechanisms for software delivery for a very large subset of applications use-cases in the coming years.
Project Fugu
The goal of Project Fugu is to make the “app gap” go away. Simply put, the idea is to bake a set of right APIs into the browser, such that over time web apps become capable of doing almost everything that native apps can - with the right levers of permissions and access-control of course, for all your rightly-raised potential privacy and security concerns!

Enough with the Thanos references, but I wouldn’t be very surprised if someone in the web community called this crazy. And if I absolutely had to, I am going to admit that even if so, this is definitely my kind of crazy. I like to think that I somehow saw this coming, and I wanted this to happen. For years, browsers have in some capacity been trying to bring bits and pieces of native power to the web with experimental APIs for things like hardware sensors and such. With Fugu, all this endeavour to impart native-level power to the web has at least been formally unified under one banner and picked up like an umbrella initiative for building and standardising into the open web by the most popular browser project there is. And I’m really excited to see this succeed for the long term! So I’d love to see this turn out like IronMan (the winning, not the dying part) rather than Thanos in the end!
The advent and success of Progressive Web Apps (PWA) would have definitely acted as a catalyst at exhibiting that with the right pedigree, web apps can really triumph. Making web apps easily installable or bringing push notifications to the web was perhaps just the first few pieces of this bigger puzzle we have been staring at for a while. Keeping aside whatever Google as a company’s strategies and business motivations may be to so heavily be investing in everything web; if at the end of the day it benefits the entire web user and developer community by making the web platform more capable, and I choose to believe that it will, I am surely going to sleep happier at night.
In case you’ve been wondering, the word “Fugu” is Japanese for pufferfish, one of the most toxic and poisonous species of vertebrates in the world, incidentally also prepared and consumed as a delicacy, which as you can guess, can be extremely dangerous from the poison if not prepared right. See what they did there?
Some of the upcoming and interesting capabilities that were announced as part of Project Fugu are:
- Native Filesystem API which enables developers to build web apps that interact with files on the users’ local device, like IDEs, photo and video editors or text editors.
- Contact Picker API, an on-demand picker that allows users to select entries from their contact list and share limited details of the selected entries with a website.
- Web Share and Web Share Target APIs which together allow web apps to use the same system-provided share capabilities as native apps.
- SMS Receiver API, using which web apps can now use to auto-verify phone numbers with SMS.
- WebAuthN to let web apps access hardware tokens (eg. YubiKey) or perform biometrics (like a fingerprint or facial recognition) based identification and recognition of users on the web.
- getInstalledRelatedApps() API that allows your web app to check whether your native app is installed on a user’s device, and vice versa.
- Periodic Background Sync API for syncing your web app’s data periodically in the background and possibly providing more powerful and creative offline use-cases for a more native-app-like experience.
- Shape Detection API to easily detect faces, barcodes, and text in images.
- Badging API that allows installed web apps to set an application-wide badge on the app icon.
- Wake Lock API for providing a mechanism to prevent devices from dimming or locking the screen when a web app needs to keep running.
- Notification Triggers for triggering notifications using timers or events apart from a server push.
The list goes on. These features are either in early experimentation through Origin Trials or targeted to be built in the future. Here is an open tracker for the list of APIs and their progress that have been captured so far under the banner of Project Fugu.
Also worth noting, webwewant.fyi was as announced as well, which is a great place for anyone in the web community to go and provide feedback about the state of the web and things that we want the web to do!
On PWAs… wait, now we have TWAs?
Progressive Web Apps with their installability and native-like fullscreen immersive experiences have been Google’s showcase fodder for over multiple years of Google I/O and Chrome Dev Summit. Major consumer facing brands like Flipkart, Twitter, Spotify, Pinterest, Starbucks, Airbnb, Alibaba, BookMyShow, MakeMyTrip, Housing, Ola, OYO have all built and shown how great PWA based experiences can be made which are hard to distinguish from native apps by the average user. By this point in time, I think as a community, we generally understand and agree that PWAs can be awesome when done right. So what next?
A key development for installable web apps has been the emergence of Trusted Web Activities (TWA) which provide a way to integrate full-screen web content into Android apps using a protocol called Custom Tabs: in our case, Chrome Custom Tabs.
To quote from the Chromium Blog, TWAs have access to all Chrome features and functionalities including many which are not available to a standard Android WebView, such as web push notifications, background sync, form autofill, media source extensions and the sharing API. A website loaded in a TWA shares stored data with the Chrome browser, including cookies. This implies shared session state, which for most sites means that if a user has previously signed into your website in Chrome they will also be signed into the TWA.
Basically think of how PWAs work today, except that you can install it from the Play Store, with possibly some other added benefits of app-like privileges. It was briefly mentioned that with TWAs the general permission model of certain web app capabilities (such as having to ask for push notification permissions) may go away and become as simple and elevated as true native Android apps (considering they are, in fact, so).
As an application of all this, TWAs are now Google’s recommended for web app developers to surface their PWA listings on the Play Store. Here’s their showcase on OYO.
Imagine having native apps that almost never need to go through painful or slow update cycles and consume very little disk space.
I believe TWAs can open up some really interesting avenues. Imagine having native apps that almost never need to go through painful or slow update cycles (or hence have to deal with all the typical complexities of releasing and maintaining native apps and their codebases), because like everything web, the actual UI and content always updates on the fly! These apps get installed on a user’s device, consume very little disk space compared to full-blown native apps because of an effectively shared runtime host (the browser) and work at full capacity of that browser, say Chrome. This is quite different from embedding WebViews into hybrid native applications for a number of reasons where the main browser on a user’s device can do more powerful things or have access to information that WebView components embedded into individual native apps can not.
If today you maintain a native app, a lite version of your native app, and a mobile website (like Facebook does); now, if you want, your lite app can be simply your mobile website distributed via the Play Store wrapped in a TWA. One less codebase to maintain. Phew.
I haven’t yet played around with deploying a TWA first-hand myself, so some of the low-level processes are still unclear to me, but from what I could gather talking to Google engineers at CDS who have been working on TWAs, because of several Play Store policies and mechanisms based on how it operates today by design, looks like as developers we still need to handcraft a TWA from a PWA, and manually upload and release it onto the Play Store. What would be amazing is being able to hook up some sort of a pipeline onto the Play Store itself that auto-vends a PWA as a TWA given a right, validated config.
Other improvements coming to PWAs are the shortcuts member in Web App Manifest which will allow us to register a list of static shortcuts to key URLs within the PWA where the browser exposes these shortcuts via interactions that are consistent with exposure of an application icon’s context menu in the host operating system (e.g., right-click, long press), similar to how native apps do.
Also, Chrome intends to play with the “Add to Homescreen” verbiage and it might probably simply be called “Install” in the future.
Because Performance. Obviously!
Not all devices are made equal.
And neither the experience of your web app.
Users access web experiences from a large variety of network conditions (WiFi, LTE, 3G, 2G, optional data-saver modes) and device capabilities (CPU, memory, screen size and resolution) which causes a large performance gap to exist across the spectrum of network types and devices. Multiple Web APIs are available today that can collectively inform us with network and device information which could be used to understand, classify and target users with an adaptive experience for providing them with an optimal journey through our website, given their state of network and device performance. Some APIs that can help us here are the Network Information API that informs effective connection type, downlink speed, RTT or data-saver information, DeviceMemory API, CPU HardwareConcurrency API and a mechanism to communicate such information as Client-Hints.
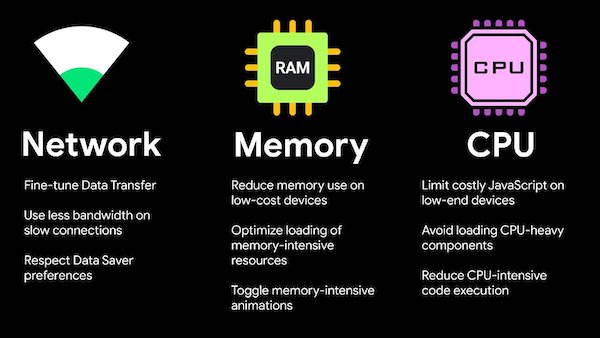
Facebook described on a very high-level their classification models for devices for both mobiles and desktops (which are relatively harder to do) and how they have been effectively using this information to derive the best user experience for targeted segments.
All this comes paired with the release of Adaptive Hooks, which makes it easy to target device and network specs for patterns around resource loading, data-fetching, code-splitting or disabling certain features for your React web app.
Better to hang by more than a thread.
The more work is required to be done during JS execution, it queues up, blocks and slows everything down effectively causing the web app to suffer from jank and feel sluggish.
To deliver web experiences that feel smooth, a lot of work needs to be done by the browser, ranging from the initial downloading, parsing and execution of HTML, CSS & Javascript; and all the successive work required to be able to eventually paint pixels on the screen which includes styling, layouting, painting and compositing; and then to make things interactive, handling multiple events and actions; and in response to that, frequently redoing most of these above tasks to update content on the page.
A lot of these tasks need to happen in sequence every time, as frequently as required, within a cumulative span of a few milliseconds to keep the experience smooth and responsive: about 16ms to deliver 60 frames per second, while some new devices support even higher refresh rates like 90Hz or 120Hz which push the available time to paint a frame to even smaller if you have to keep up with the refresh rate.
With the combined truth that all devices are not made equal and that JavaScript is single-threaded by nature which means the more work is required to be done during JS execution, it queues up, blocks and slows everything down effectively causing your web app to suffer from jank and feel sluggish.
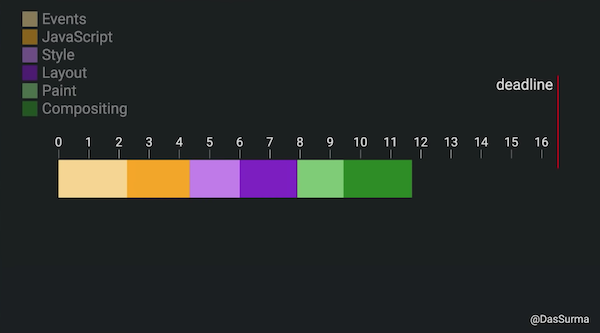
Patterns to effectively distribute the amount of client-side computational work across multiple threads by leveraging web workers to perform Off-Main-Thread (OMT) work and keep the main (UI) thread reserved for doing only the amount of work that absolutely needs to be done by it (DOM & UI work) can help significantly to alleviate this problem. Such patterns are about reducing risks of delivering poor user experiences, where although the entire time of overall work completion maybe, in fact, slowed marginally my message-passing overheads across multiple worker threads, the main (UI) thread is instead free to do any UI work required in the interim (even new user interactions like handling touch or scrolls) and keep delivering a smooth experience throughout. This works out great since the margin of error of dropping a frame is in the order of milliseconds while the making the user wait for an overall task to complete can go into the order of 100s of milliseconds.
Web workers have existed for a while but somehow for probable reasons around their wonkiness, they haven’t really seen great adoption. Libraries like Comlink can help a lot to that end.
Proxx.app is a great example to look at all of this in action.
Lighthouse shines brighter!
Not to throw any shade at Lighthouse (all puns intended), so far this web performance auditing tool had always fallen short of my expectations for any practical large-scale use-case. It seemed a little too simple and superficial to be of much use to drive meaningful insights in complex, real-world production applications. Don’t get me wrong, Lighthouse has always been a decent product on its own, but building web performance test tooling that is robust, powerful and predictable, is inherently a hard problem to solve. Lighthouse had always been somewhat useful to me, but mostly as a basic in-browser audit panel thing that could give me some generic “Performance 101” insights, rather than something I would be excited to hook up as a powerful-enough synthetic performance testing tool in a production pipeline for catering to deeper performance auditing needs that I may have.
Hopefully, that changes now. With the release of Lighthouse CI, an extension of the toolset for automated assertion, saving and retrieval of historical data and actionable insights for improving web app performance though continuous integrations, the future seems a bit more brighter.
What’s even more exciting, is the introduction of stack-packs which detect what platform a site is built on (such as Wordpress) and displays specific stack-based recommendations, and plugins which provide mechanisms to extend the functionality of Lighthouse with things such as domain-specific insights and scoring, for example, to cater to the bespoke needs of an e-commerce website.
… and comes with new Performance Metrics.

With Lighthouse 6, some important changes are coming to how it scores web page performance, focusing on some of the new metrics that are being introduced:
- Largest Contentful Paint(LCP), which measures the render time of the largest content element visible in the viewport.
- Total Blocking Time (TBT), a measure of the total amount of time that a page is blocked from responding to user input, such as mouse clicks, screen taps, or keyboard presses. The sum is calculated by adding the blocking portion of all long tasks between First Contentful Paint and Time to Interactive. Any task that executes for more than 50ms is a long task. The amount of time after 50ms is the blocking portion. For example, if Chrome detects a 70ms long task, the blocking portion would be 20ms.
- Cumulative Layout Shift (CLS), which measures the sum of the individual layout shift scores for each unexpected layout shift that occurs between when the page starts loading and when its lifecycle state changes to hidden. Layout shifts are defined by the Layout Instability API and they occur any time an element that is visible in the viewport changes its start position (for example, it’s top and left position in the default writing mode) changes between two frames. Such elements are considered unstable elements.
Metrics that are being deprecated are First Meaningful Paint(FMP) and First CPU Idle (FCI).
Visually marking slow vs. fast websites
Chrome has expressed plans to visually indicate what it thinks is a slow vs. a fast loading website. The exact form of how the UI is going to look like is still uncertain, but we can expect a bunch of trials and experiments from Chrome on this.
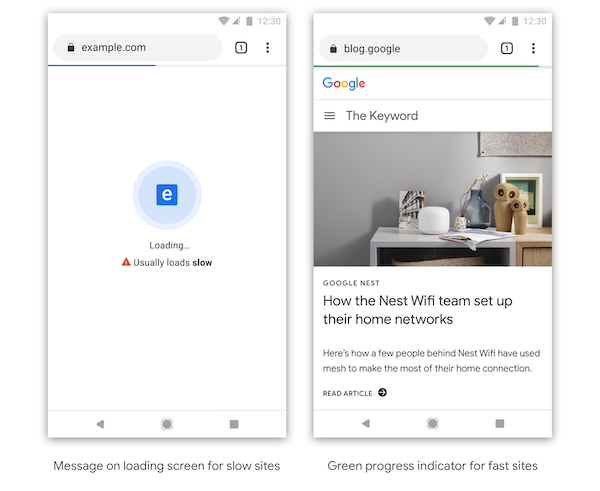
I guess that this is going to be mired with some controversy when this happens. How does the browser judge what is right for my website? Why does it get to decide where exactly to draw the line? And how exactly does it do it for the type of website, target audience and content I have? Surely there are a lot of difficult questions with no easy answers yet, but there’s one thing for sure, that if this does happen, it will force the average website to take some web performance considerations more seriously. Somewhat like when browsers together decided to start enforcing HTTPS by visually penalizing non-secure websites and it worked out well eventually. Honestly, with so much that is unclear, for now, I am still going lean towards the side of more free will, but as a self-appointed advocate of web performance, I am very tempted to think that if executed right, this might just be a good thing.
Web Framework ecosystem improvements
Google has been partnering up with popular web framework developers to make under-the-hood improvements to those frameworks such that sites that are built and run on top of these frameworks get visible performance improvements without having to lift a finger so to speak.
Choosing to deliver modern Javascript code to modern browsers could visibly improve performance.
The prime example of this was a partnership with Next.js, a popular web framework based on React, where a lot of development has happened around improved chunking, differential loading, JS optimisations and capturing better performance metrics.
An interesting (though quite seemingly obvious in retrospect) takeaway from this was choosing to deliver modern Javascript code to modern browsers (as opposed to lengthy transpiled or polyfilled code based on some lowest common denominator of browsers you need to support) could visibly improve performance by drastically reducing the amount of code that is shipped. This was coupled with the announcement of Babel preset-modules which can help you achieve this.
If you are interested, the Framework Fund run by Chrome has also been announced multiple times across this CDS.
How awesome is WebAssembly now?
Spoiler alert: pretty awesome! 💯
{kind=link}
WebAssembly (WASM) is a new language for the web that is designed to run alongside Javascript and as a compilation target from other languages (such as C, C++, Rust, …) to enable performance-intensive software to run within the browser at near-native speeds that were not possible to attain with JS.
While WebAssembly has been out there being developed and improved upon for a few years, it saw a major announcements this time on performance improvements that brings it closer to being at par with high-performance native code execution, being enabled through the browser’s WASM engine improvements such as implicit caching, introduction of support for threads, and SIMD (Single Instruction Multiple Data) which is a core capability of modern CPU architectures that enables instructions to be executed multiple times faster.
Multiple OpenCV-based demos that illustrated real-time high-FPS feature recognition, card reading and image information extraction, facial expression detection or replacement within the web browser, all of which have been made possible by the recent WASM improvements, were showcased.
Check them out, some of them are really cool!
The cake is still a lie, but a delicious one at that!
Here, if you didn’t get that reference.
One of the unique new web platform capabilities that garnered a lot of interest was Portals, which aims to enable seamless and animation-capable transitions across page navigations for multi-page architecture (MPA) based web applications, effectively affording such MPAs a creative lever to provide smooth and potentially “instantaneous” browsing experiences like native apps or single-page applications (SPA) could provide. They can be used to deliver great app or SPA-like behaviour without the complexity of doing a SPA which often becomes cumbersome to scale and maintain for large websites and with complex and dynamic use-cases.
Portals are essentially a new type of HTML element that can be instantiated and injected in a page to load another page inside it (in some form similar to IFrames but also different in a lot of ways), keep it hidden or animate it in any form using CSS animations, and when required, navigate into it - thus performing page navigations in an instant when used effectively.
An interesting pattern with Portals is that it can also be made to load the page structure (skeleton or stencil, as you may also call it) preemptively even if the exact data is not prefetched and perform a lot of the major tasks of computation (parsing, execution, styling, layout, painting, compositing) for most of the document structure that contributes to web page performance, in effect moving the performance costs of these tasks out-of-band of critical page load latencies, such that when a portal navigation happens, only the data is fetched and filled in onto the page. This would also require some rendering costs but typically much lesser than the entire page’s worth of work.
Several demos are available and this API can be seen behind experimental flags in Chrome at the moment.
Web Bundles
In the simplest terms, a Web Bundle is a file format for encapsulating one or more HTTP resources in a single file. It can include one or more HTML files, Javascript files, images, or Stylesheets. Also known as Bundled HTTP Exchanges, it’s part of the Web Packaging proposal (and as someone wise would say, not to be confused with webpack).
The idea is to enable offline distribution and usage of web apps. Imagine sharing web apps as a single .wbn file over anything like Bluetooth, Wi-Fi Direct or USB flash drives and then being able to run them offline on another device in the web application’s origin’s context! In a way, this sort of again veers into the territory of imparting the web more powers like native apps which are easily distributable and executable offline.
In such countries, a large portion of apps that exist on people’s phones get side-loaded over peer-to-peer mechanisms rather than from over a first-party distribution source like the Play Store.
If you researched on different modes in how native apps get distributed in countries with emerging markets such as in India, Mid-East or Africa which are heavy on mobile users but generally deprived on public Wi-Fi availability or have predominantly poor, patchy or congested cellular networks, peer-to-peer file-sharing apps like Share-It or Xender are extremely popular in terms of how people share software and a large portion of apps that exist on people’s phones get side-loaded over peer-to-peer mechanisms rather than from over a first-party distribution source like the Play Store. Seems only natural that this would be a place to catch on for web apps as well!
I need to confess that the premise of Web Bundles does sort of remind me of the age-old MHTML file format (.mhtml or .mht files if remember those) that used to be popular a decade back and in fact, is still supported by all major browsers. MHTML is a web page archive format that could contain HTML and associated assets like stylesheets, javascript, audio, video and even Flash and Java applets of the day, with their content-encoding inspired from the MIME email protocol (leading to the name MIME HTML) to combine stuff into a single file.
For what it’s worth though, from the limited knowledge that I have so far, I do believe that what we’ll have with Web Packaging is going to be much more complex and powerful and catering to the needs of the Web of this generation with key differences like being able to run in the browser using the web application’s origin’s context (by being verified using signatures similar to how Signed HTTP Exchanges may work) rather than being treated as locally saved content like with MTHML. But yeah… can’t deny that it does feel a bit like listening to Backstreet Boys again from those days! Hashtag Nostalgia.
More cool stuff with CSS! Yeah!
I didn’t even try to come up with a better headline for this section, because this is simply how I genuinely feel.
New capabilities
A quick list of some of the new coolness that’s landing on browsers (or even better, have already landed) are:
scroll-snapthat introduces scroll snap positions, which enforce the scroll positions that a scroll container’s scrollport may end at after a scrolling operation has completed.:focus-withinto represent an element that has received focus or contains an element that has received focus.@media (prefers-*)queries, namely theprefers-color-scheme,prefers-contrast,prefers-reduced-motionandprefers-reduced-transparency, which in Adam Argyle’s words, can together enable you to serve user preferences like, “I prefer a high contrast dark mode motion when in dim-lit environments!” 😎position: stickywhich is a hybrid of relative and fixed positioning, where the element is treated asrelativepositioned until it crosses a specified threshold, at which point it is treated asfixedpositioned.- CSS logical properties to provide the ability to control layout through logical, rather than physical, direction and dimension mappings. Think of dynamic directionality based on whether you’re serving
ltr,rtlorvertical-rlcontent. Here’s a nice article that talks about it.
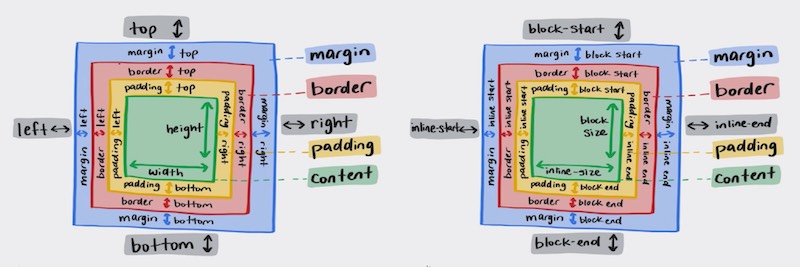
:is()selector, the new name for the Matches-Any Pseudo-class.backdrop-filterwhich lets you apply graphical effects such as blurring or colour shifting to anything in the area behind an element!
Houdini
...creating new CSS features without waiting for them to be implemented natively in browsers.
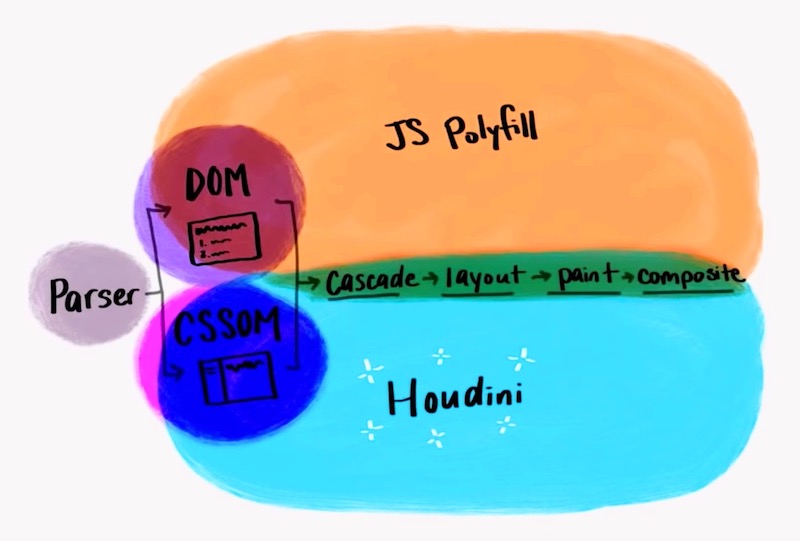
CSS Houdini has perhaps for some time been at the top of my hot-new-things list when thinking about the exciting future of the web. As MDN describes it, Houdini is a group of APIs being built to give developers direct access to the CSS Object Model (CSSOM) and enabling them to write code the browser can parse as CSS, thereby creating new CSS features without waiting for them to be implemented natively in browsers.
In other words, it’s an initiative to open up the browser in a way that gives web developers more direct access to be able to hook into styling and layout process of the browser’s rendering engine. And let creativity (with performance) run amok!
If this is the first time you are hearing about CSS Houdini, take a few moments to let that sink in. Believe me. Then if you like, read a few other great articles on it.
It’s relatively still quite early in the world of Houdini in terms of cross-browser support, but a few announcements on some good progress were made. Paint API, Typed OM and Properties and Values API have shipped to Chrome. Layout API is in Canary.
Check out the cool Houdini Spellbook or the ishoudinireadyyet.com website for more.
Showing some ❤ to HTML
Form elements
In HTML, the visual redesign, accessibility upgrade and extensibility of form elements such as <select> or <date> is a welcome development! A joint session by Google and Microsoft described what to expect with the customizability of form elements in the future, or even the possibility of new elements that don’t exist yet, like table-views or toggle-switches.
Display Locking
Web content is predominantly large amounts of text and images, and if you think about it, often just a collection of list views of a few common types of components repeating over and over again. Think about your Facebook or Twitter feed, your Google or Amazon search results, a lengthy blog (like this one?) or a Wikipedia article you’re reading, or pretty much every other popular website that you use. There is a lot of scrolling involved!
This demands the notion of Virtual Scrolling, and one of the possible prototypes is a new web platform primitive called Display Locking, which is a set of API changes that aim to make it straightforward for developers and browsers to easily scale to a large amount of content and control when rendering work happens.

To quote from Nicole Sullivan from the session on this, Display Locking allows you to do batch rendering updates to avoid paying the performance costs when handling large amounts of DOM; it also means that locked sub-trees are not rendered immediately, which means you can keep more stuff in the DOM; and that’s great because it becomes searchable both by Find in Page as well as by assistive technologies.
Safety and Privacy
Visual updates to URL display
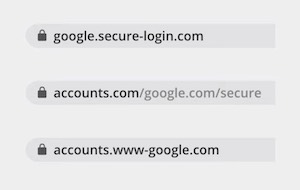
Let’s talk about important stuff. In the dimension of safety and privacy, some notable callouts include Chrome’s experiments around the general web consumer’s perception of security models related to how URL information is displayed by the browser.
Chrome’s past attempts on using extended validation indicator which informs the legal entity tied to a domain name did not turn out to be successful, simply because people don’t notice when it’s missing.

This also calls out studies where the average web user has been found out to not necessarily clearly understand visual cues like what the HTTPS padlock icon on the URL bar means.
All of this comes with a degree of potential controversy though, where Chrome as a browser will start hiding complete URLs and show origin information that it feels is the most relevant for the average web user. This is probably not going to make more experienced users very happy. In its defence, Chrome announced the Suspicious Site Reporter extension that will allow the power user to see the full unedited URL, as well as report malicious sites to Google’s Safe Browsing service. While the intentions are great, this still feels somewhat stop-gap and a little unfulfilling to me. Simply because mobile has been always so hugely important and non-desktop versions of Chrome have so far, to the best of my knowledge, have had literally zero history of supporting extensions, this sounds like a hasty half-measure and an uncanny oversight. Wouldn’t something as simple as a browser setting have made things easier? Perhaps there are motivations here that I don’t fully understand.
Combating sophisticated spoofing attacks
Sophisticated spoofing attacks like IDN spoofing is extremely difficult for the average web user to detect, and for that matter, often likely to easily defeat the technically experienced user as well unless they are specifically looking for it.

Chrome is introducing what it calls lookalike warnings to inform the user of potential attacks and then try to redirect them to the possibly intended website instead.
Committed to privacy, but with ads? 🤷♀️
Following a brief stint on why we should all look at ads as a necessary evil, it was announced that there are [sic] restrictions coming to third-party cookies in Chrome. New cookie classification spec that’s landing enforces SameSite=None to be explicitly set to designate cookies intended for cross-site access, without which they will be by default accessible only in first-party contexts. Coupled with the Secure attribute, this makes cookies only accessible over HTTPS connections. Read more about it on blog.chromium.com.
In a world where other more privacy-focused browsers like Firefox or Safari have been blocking third-party cookies by default and have shown committed interest in fighting against fingerprinting, all this seems arguably feeble. Then again, not that it has had a great track record.
Chrome Extensions
…making progress towards the way they should have ideally always been.
Themes of privacy and safety continued into the presentation of the newer mechanisms for building Chrome extensions that are being designed to be more protective about security and access control.
The introduction of Extension Manifest V3 along with other overhauls to the extension ecosystem architecture would hopefully deprecate currently existing permission models and background code executions which traditionally have been overtly open and also known to cause performance bottlenecks. Stricter models for both permissions and execution limits through background service workers are being introduced.
A notable mention here was the addition of the declarative net request model that will drastically change the behaviour of request interception and blocking as done today by Chrome extensions (such as AdBlock) and provide more restrictive and performant models to achieve the same.

SEO
Google announced that the Googlebot crawler user-agent would be updated soon to reflect the new evergreen Googlebot. A much-needed improvement over the previous rendering engine used by Googlebot that was based on Chrome 41 and had been probably facing a lot of difficulties keeping up with new Javascript heavy websites of today.
What this basically means is that with every release of Chrome, the Googlebot rendering engine will also keep up and get updated. Consequentially, this also gets coupled with the update of the Googlebot user-agent string which will now not always continue to match with an exact version of Chrome anymore, as used to be the case before.
Benefits include better support for modern ways of building websites using such as with Javascript rendered pages, lazy-loading and the support for web components.
Also, going ahead, images set as background-image URLs may not be indexed.
Other stuff to call out…
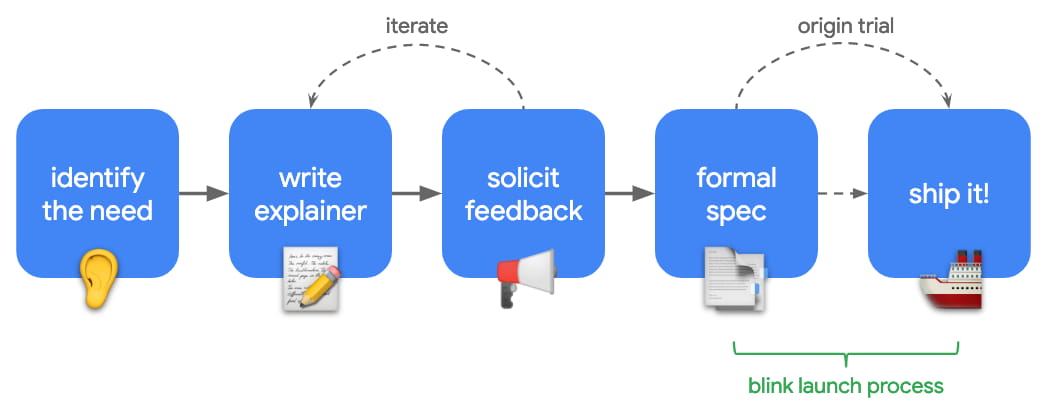
The Blink shipping process
I wouldn’t really bother trying to explain this considering there’s a great video and write-up that already does a much better job at it. If you are interested in learning how the web platform works in terms of new feature proposals, addition and review of web standards and how features are shipped to Blink (Chromium’s rendering engine) and how it complements the web standards process, check them out.
Origin Trials
This isn’t really news, but to the uninitiated, “Origin trials” are Chrome’s way to quickly experiment and gather feedback on new and potentially upcoming web features by providing some partner websites early access to try out early implementations and give feedback on usability, practicality, and effectiveness that eventually goes on its way to the web standards community.
APIs exposed through Origin Trials are unstable by intent (prone to changes) and at one point before the end of the trials, go out of availability briefly. They also have inbuilt safeguarding mechanisms to get disabled if 0.5% of Chrome’s page loads start accessing the API, to prevent such experimental APIs from being exposed or baked too much into the open web before they are done right and become standards. For more information, see the explainer, developer guide or blink documentation.
If you are interested in playing around with a hot new API that’s landing on Chrome but far from general availability, this is your way to go!
Context Indexing API
Here comes that one-off API that I didn’t really quite know where to put. The idea is to enable indexing of offline content that you can present to a user, but to be able to effectively do that, request the browser to index them such that they can be surfaced in prominent places like Chrome’s landing page or other places, collectively known as “Discovery” experience. Check out the proposal to learn more.
That’s all folks!